
Python is often perceived as a language in which everything happens «by itself». I wrote the code and got the result. However, this «simple» process actually involves a multi-stage transformation mechanism.
Each line goes through a series of changes, from designs that are easy for humans to understand to instructions that machines can understand. In this article, we'll take a look at how Python actually works and what happens when you click «Run».
When you type the Python command script.py in the terminal, the Python interpreter (the standard CPython implementation) is launched. Python code execution does not start instantly — at first there are several preparatory stages.
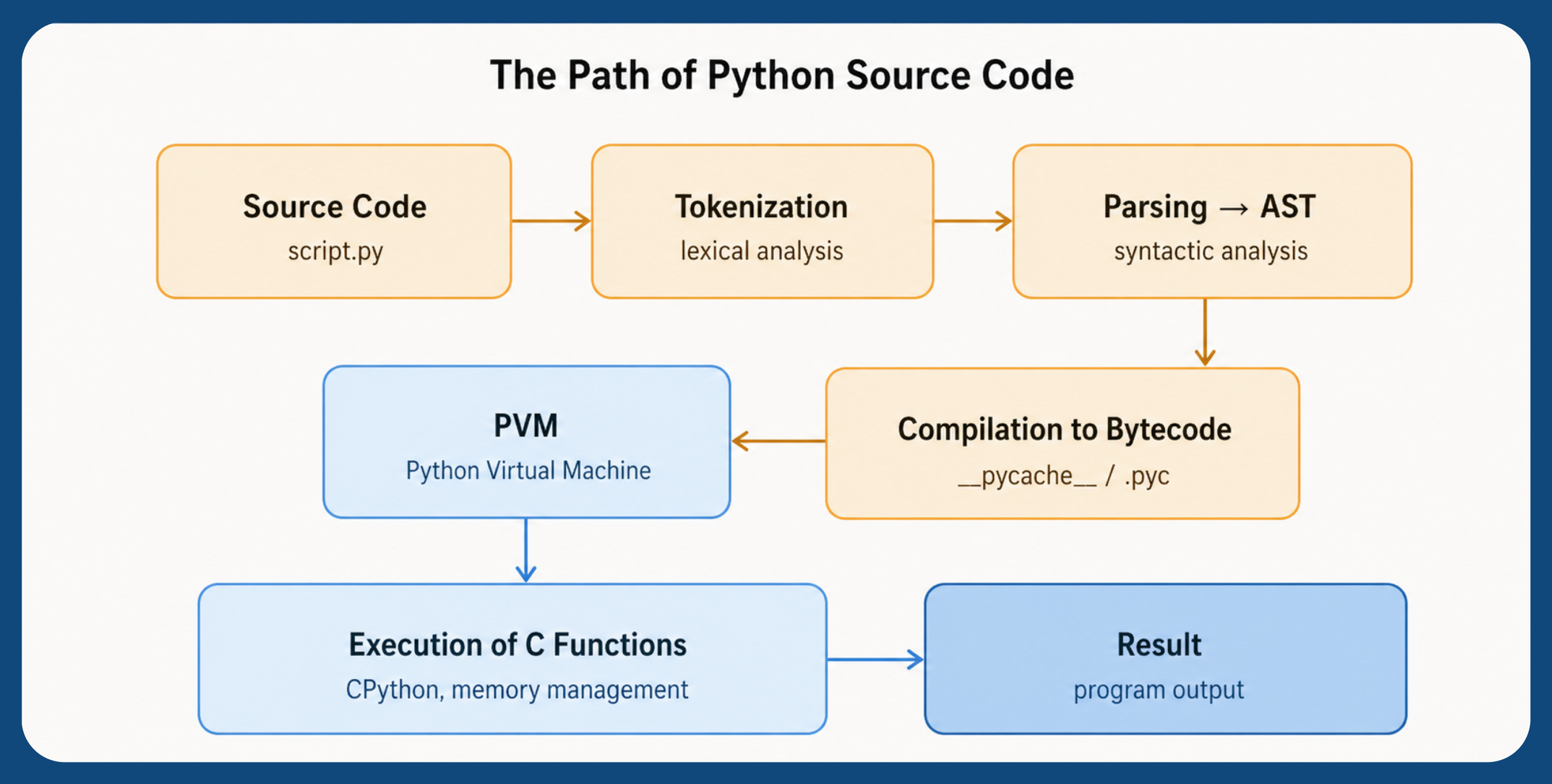
Python is traditionally classified as an interpreted language, but its work is more complicated: before execution, the code is compiled into an intermediate representation, bytecode, which is then executed by the Python virtual machine.
Let's analyze each stage in detail.
The first stage of CPython's work is compiling the source code into bytecode. It includes several consecutive steps.
The source code of the program is divided into the minimum significant elements — tokens: keywords, identifiers, operators and brackets. Comments and minor spaces are ignored at this stage, but indentation is part of the syntax in Python.
The received tokens are converted into an abstract syntax tree (AST), a structure reflecting the logic of the program. If there are syntax errors in the code (for example, a colon is missing or indentation is broken), they are detected at this stage.
The CPython compiler then traverses the AST nodes and generates bytecode instructions, a low-level representation of a program designed to be executed by a Python virtual machine. That is why Python can be considered a compiled language in a certain sense.
A bytecode is a low-level set of instructions that does not depend on the architecture of the operating system or processor. It serves as an intermediary between the source code and its execution.
Compiled files are saved with the extension.pyc in the __pycache__ directory. If the source file has not been changed, Python uses ready-made bytecode on subsequent runs, which reduces the program start time.
Bytecode is not machine code executed by a processor. It is intended to be executed inside the interpreter. Additional tools such as Cython or Nuitka are used to convert Python code into native machine code.
After generating the bytecode, control is transferred to the Python Virtual Machine (PVM), the virtual machine responsible for its execution. PVM is a stack interpreter that sequentially reads and executes bytecode instructions.
Its work is based on stack architecture. For example, when adding two numbers, the values are first placed on the stack, then the corresponding operation is performed, after which the result is returned to the top of the stack and used in further calculations.
Most everyday operations, such as string concatenation, working with lists, or mathematical calculations with built-in types, are implemented in CPython in C.
When you call the my_list.append(1) method, the Python virtual machine (PVM) does not interpret the logic of adding an element at the Python level. Instead, it turns to an optimized C function that directly manages memory and performs the operation as efficiently as possible. This approach allows you to combine the convenience of Python with the performance of low-level languages.
The issue of Python performance is related to its architectural features. To better understand the differences, let's compare Python with compiled languages such as C and C++.
In languages like C++, the type of a variable is known at the compilation stage. In Python, for each operation, for example, a + b, the interpreter must determine:
These multiple runtime checks create additional overhead costs.
PVM must process each bytecode instruction right at runtime. Modern JIT compilers (like in PyPy or V8 in JavaScript) try to optimize this, but classic CPython works that way.
This is a «lock» that allows only one thread to control the Python interpreter at a time. This simplifies memory management, but prevents Python from efficiently using multi-core processors for parallel computing in CPU-bound tasks.
Python automatically manages memory using Reference Counting and the Garbage Collector. Although this saves the developer from having to manually release resources, such mechanisms require additional computing costs.
Despite the slowness of pure Python, libraries like NumPy, Pandas, and TensorFlow are ten times faster. The secret is that their computationally heavy parts are not implemented in pure Python.
1. Libraries in C/C++/Rust. NumPy and Pandas use arrays and internal data structures implemented in low-level languages. When you call np.array([1, 2, 3]). sum(), Python delegates the calculation to a fast C function that works directly with memory.
2. Vectorization of operations. Instead of the for loop in Python, which iterates slowly, NumPy performs an operation on the entire array at once through optimized C code.
3. Minimum type checks. In C libraries, data types are fixed in advance (for example, float64), so you don't need to check the types on the fly.
# Slowly (pure Python)
result = sum([i * 2 for i in range(1000000)])
# Quickly (NumPy, in 50-100 times)
import numpy as np
result = np.sum(np.arange(1000000) * 2)Python sacrifices speed for flexibility, but delegates heavy computing to fast libraries.
Python was originally designed not as a replacement for C or Java, but as a language in which code is written quickly and read easily. The speed of execution here is deliberately sacrificed to the speed of development.
The layered architecture adds overhead, but gives flexibility — the same code runs on Windows, Linux, and macOS unchanged. Where performance is critical, Python simply delegates work to libraries in C, C++, and other low-level languages (NumPy, pandas, and PyTorch use just such implementations under the hood).
It turns out to be a curious construction: you write in Python, and the compiled code performs heavy calculations. This explains why the language has taken root equally well in the web backend, machine learning, and scientific computing, areas with completely different performance requirements.
From a technical point of view, Python can be considered compiled into bytecode, but not directly into machine code. This is why it is often referred to as an interpreted language with pre-compilation. This hybrid approach ensures portability and ease of development while maintaining an acceptable level of performance.
100 тыс.+ пользователей и 3000 часов разработки — Flutter MVP за 3 месяца

Тысячи скачиваний и шорт-лист Рейтинга Рунета — экосистема доставки еды на Flutter для Пхукета

